
For a full list of BASHing data blog posts, see the index page. ![]()
Two ugly CSVs
Hard to parse, harder to analyse. The Australian Electoral Commission issues annual reports on political donations: who gave how much to whom, and when. I downloaded the 2017-2018 data table "AnalysisDonor.csv" as a CSV from the AEC website on 21 March 2019.
The CSV begins with a couple of metadata lines, then a header line with field names, then 2108 one-line donation records. The record lines are in "all-items-double-quoted" format but the header has no quotes at all — it isn't formatted like the rest of the table. Furthermore, every line in the file ends with a comma (why?) and a Windows carriage return. Getting the table minus the metadata lines into clean TSV format as the new file "ad1" takes several commands:
tail -n +3 AnalysisDonor.csv | tr -d '\r' | sed 's/^"//;s/","/\t/g;s/",$//' | sed '1s/,$//;1s/,/\t/g' > ad1
The tail command strips off the first two (metadata) lines. The tr command deletes the Windows carriage returns. The first sed command works on the record lines and deletes the initial quote, replaces the field-separating "," with a tab, and deletes the terminal ",. The second sed command works on the header (now line 1, with the metadata lines gone) and first deletes the terminal comma, then replaces the field-separating commas with tabs.
There are eight tab-separated fields in "ad1":
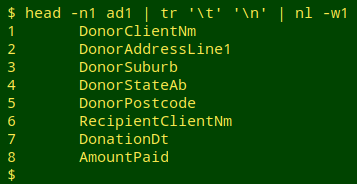
Each of these fields has problems, but I doubt that's because the AEC wants to make it harder to analyse political donations. I blame incompetence insufficient attention to data quality and the FAIR principles.
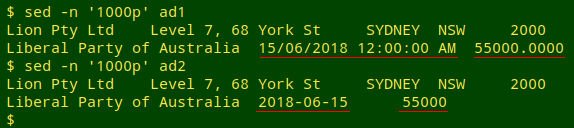
The last two fields are fairly easily fixed. Field 7, donation date, is formatted as DD/MM/YYYY 12:00:00 AM in all but one of the 2108 records (date is blank in that record). Dates can be converted to the sortable ISO 8601 format YYYY-MM-DD with a couple of string operations. Field 8, which is donation amount, is bizarrely formatted as ...D.CCcc, for example "1100.0000". Does anyone really donate hundredths of cents to political parties? Anyway, the last two fields can be made sensible with an AWK command, generating the new file "ad2":
awk 'BEGIN {FS=OFS="\t"} NR>1 && $7 != "" {split($7,a," "); split (a[1],b,"/"); $7=b[3]"-"b[2]"-"b[1]; $8=int($8)} $7 == "" {$8=int($8)} 1' ad1 > ad2
In the BEGIN statement the field separator is set to a tab for both input and output.
In lines after the header where field 7 isn't blank, field 7 is first split into "DD/MM/YYYY" and "12:00:00 AM" based on the space between them, with the pieces going into the array "a".
The first piece in "a" (the date) is then split on the separator "/" into DD, MM and YYYY, with the pieces going into array "b".
Next, AWK replaces field 7 with YYYY[hyphen]MM[hyphen]DD, and field 8 with the integer part of the donation amount.
The one record with field 7 blank is printed as-is apart from getting the whole-dollars part of the amount paid.
The final "1" tells AWK to print all lines. The header line is printed as-is, because it doesn't satisfy either of the two special conditions, NR>1 && $7 != "" and $7 == "".
Before and after:
The recipient name field (6) contains many pseudo-replicates and a truncation or two. Examples:
Liberal Party of Australia - LIB-SA
Liberal Party of Australia (S.A. Division)
Liberal Party of Australia (SA Division)
LIB-SA Liberal Party of Australia (SA Division)
LIB - SA
LIB-SA
Liberal Party of Australia (VIC Division) (paid to Enterprise Vi
#64 characters; see below
National Party of Australia - NAT-NSW
National Party of Australia - NSW
National Party of Australia - N.S.W.
NAT-NSW
The donor address fields (3-5) could use normalising for case. Examples:
Adelaide SA 5000
ADELAIDE SA 5000
City East QLD 4002
CITY EAST QLD 4002
North Sydney NSW 2060
NORTH SYDNEY NSW 2060
And the donor name (field 1) has truncated entries at or near the upper observed limit of 64 characters:
Australian Hotels Association Tasmanian Hospitality Associat #60 characters
Construction, Forestry, Maritime, Mining and Energy Union Nation #64
The Star Entertainment Group Limited (formerly Echo Entertainmen #64
Finally, for interest's sake, here are the top 10 donors to Australian political parties in 2017-2018, according to the AEC:
awk -F"\t" 'NR>1 {a[$1]+=$8} END {for (i in a) print i FS a[i]}' ad2 | sort -t $'\t' -nrk2 | head
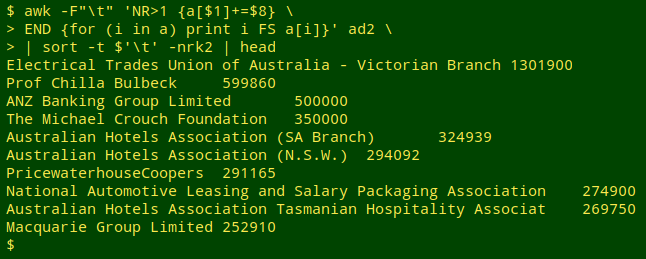
AWK ignores the header line (NR>1) and builds an array a whose index is donor name ($1) and whose value is the cumulative sum of that donor's donations ($8). After processing all the records, AWK prints the donor names and their associated total donations, separated by a tab. These are sorted in reverse numerical order of the second field (-nrk2) after sort is told that the field separator is a tab (-t $'\t'). The top 10 entries are grabbed by head.
Multiple quotes. The UK government agency Companies House offers free data tables, updated monthly, with information about UK companies. I looked at the offering for March 2019. The data is zipped and divided into separate files for ease of downloading. Here's what Companies House says about their choice of data format:
Why is the download in CSV format?
In order to keep things as simple as possible and ensure the widest possible compatibility, we have provided the file in CSV (comma separated value) format which commonly available software (such as MS Excel) is able to import automatically. It is also 'human-readable'.
Human-readable? I wonder if they mean human-readable, unlike that horrible JSON format? In any case, Companies House uses a valid version of "all-items-double-quoted" for the data, which is easily converted to the even simpler tab-separated format (TSV) with a sed command:
sed 's/^"//;s/","/\t/g;s/"$//'
However, the header line, as in the AEC CSV above, contains no quotes at all, and 14 of the 55 field names in the header have a leading whitespace. (The leading-whitespace issue is header-specific and hasn't been carried over into the non-header lines.)
A bigger problem with the dataset is multiple quoting. In what follows I've renamed "BasicCompanyData-2019-03-01-part1_6.csv" as "bcd1" for simplicity; it contains a header and 849,999 one-line records. In "bcd1", the first-prize winner in the excessive quoting category is Bell Medical Services:
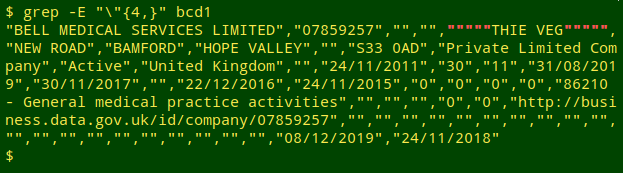
The data table also contains hundreds of records with unnecessary double quotes:
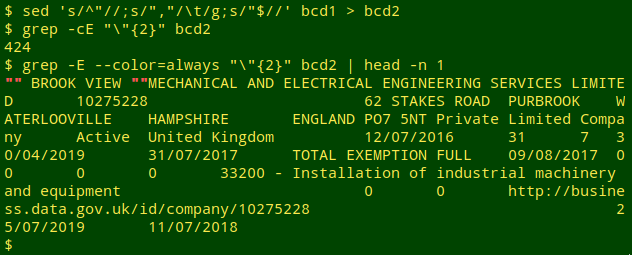
which sometimes appear as isolated strings:
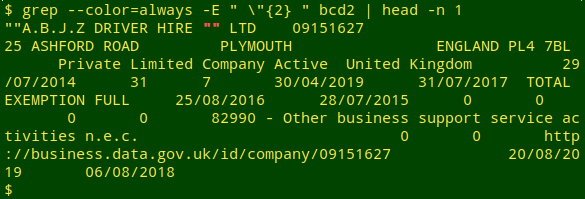
I'm not sure how all the double quoting originated, but it makes for an ugly CSV.
Many thanks to Gabriele Simeone for this example.
Last update: 2019-04-28
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License