
For a full list of BASHing data blog posts, see the index page. ![]()
Data from dingbats: copying down
My wife recently received a spreadsheet with entries as shown in this screenshot:
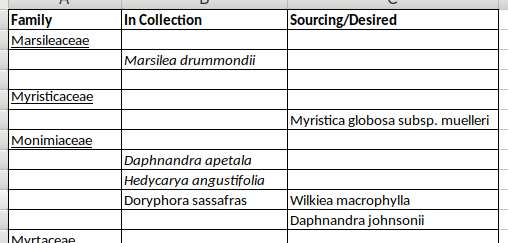
It's a good example of the IT misdemeanor Grossly Inappropriate Use of a Spreadsheet, because the list with its odd formatting and layout could just as well have been sent as a word-processor document, and in a spreadsheet the list is useless without data cleaning.
You can't prevent dingbats from managing data, but you can sometimes fix their messes. I'll rewrite this case in point as an even uglier file, "ding":
| Group | Type | Variety |
| grains | ||
| wheat | ||
| Beckom | ||
| millet | ||
| fruits | ||
| apple | Royal Gala | |
| Pink Lady | ||
| pear | ||
| poultry | chicken | |
| turkey |
which I want to tidy up as
| Group | Type | Variety |
| grains | wheat | Beckom |
| grains | millet | |
| fruits | apple | Royal Gala |
| fruits | apple | Pink Lady |
| fruits | pear | |
| poultry | chicken | |
| poultry | turkey |
Notice that I've been inconsistent: sometimes an item is offset by one line ("apple" from "fruits", "Beckom" from "wheat"), sometimes it isn't ("chicken" on the same line as "poultry", "Royal Gala" on the same line as "apple").
Repairing this file will involve re-aligning data items and copying down items to blanks in the next record. For all the fixes I'll use AWK on the command line, although in this case (and in small files generally) the repairs are easily done in a spreadsheet.
Blank lines, like the one between lines 2 and 4 in "ding", can be deleted with awk NF.
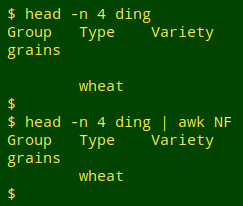
"NF" is the AWK built-in variable for "number of fields". The command awk NF is shorthand for Does NF exist in this line? In other words, is NF larger than zero? If so, print the line, otherwise don't.
The next step is to fill down in field 1:
awk NF ding | awk 'BEGIN {FS=OFS="\t"} NR>1 && $1 != "" {a=$1} $1 == "" {$1=a} 1'
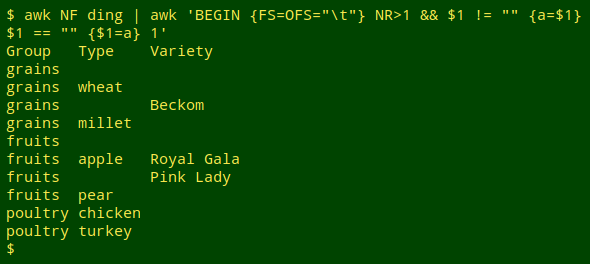
The BEGIN statement tells AWK that both the input and output fields are tab-separated. This is necessary because AWK will re-build some of the lines in "ding" and needs to be told how. The "1" at the end of the command tells AWK to print every line. There are two condition+action sections in the command. The first condition looks at lines after the header line (NR>1) and checks to see if field 1 isn't blank. If it isn't, the variable "a" is set equal to the contents of field 1. The second condition applies to lines in which field 1 is blank (so the header line is excluded). In these lines field 1 is filled with "a", thus copying down in field 1. When the next filled-field-1 line is reached, "a" is re-set for that line.
Next I'll remove any lines with nothing in fields 2 and 3:
awk NF ding | awk 'BEGIN {FS=OFS="\t"} NR>1 && $1 != "" {a=$1} $1 == "" {$1=a} 1' | awk '!($2 == "" && $3 =="")'
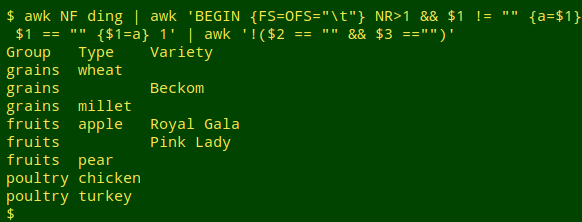
The new AWK command just selects the lines which don't have both field 2 and field 3 blank. Since the lines aren't being re-built, the output field separator (OFS) doesn't have to be specified.
Now to fill down in field 2:
awk NF ding | awk 'BEGIN {FS=OFS="\t"} NR>1 && $1 != "" {a=$1} $1 == "" {$1=a} 1' | awk '!($2 == "" && $3 =="")' | awk 'BEGIN {FS=OFS="\t"} NR>1 && $2 != "" {b=$2} $2 == "" {$2=b} 1'
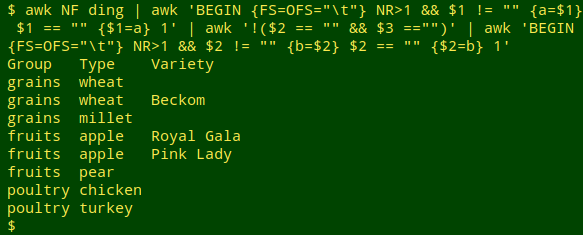
The added command is a repeat of the field 1 copy-down one, this time for field 2.
The last step is tricky. I want to delete any lines like "grains[tab]wheat" where the next line has the same field 1 and field 2 but field 3 is filled, as in "grains[tab]wheat[tab]Beckom". AWK can be made to look ahead one line, but another way to do this is to reverse the line order with tac:
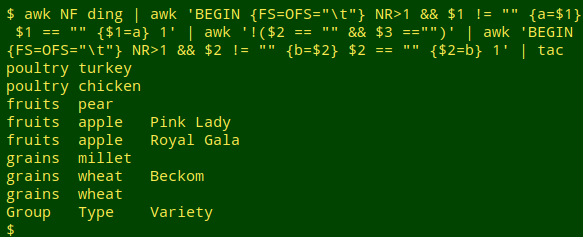
AWK can now process the file line by line, looking to see where field 3 is first filled, then empty, while fields 1 and 2 don't change. After that, the line order can be restored with another dose of tac:
awk NF ding | awk 'BEGIN {FS=OFS="\t"} NR>1 && $1 != "" {a=$1} $1 == "" {$1=a} 1' | awk '!($2 == "" && $3 =="")' | awk 'BEGIN {FS=OFS="\t"} NR>1 && $2 != "" {b=$2} $2 == "" {$2=b} 1' | tac | awk '$3 != "" {a=$1; b=$2} $1==a && $2==b && $3 == "" {a=""; b=""; next} 1' | tac
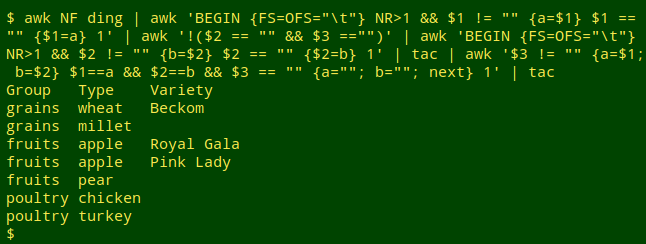
Again no re-building needed. Each time AWK finds a line with field 3 filled, it sets "a" equal to the field 1 contents and "b" equal to the field 2 contents. When it finds a line with the same field 1 and field 2 and a blank field3, it ignores the line (next) after re-setting "a" and "b" to empty strings.
Well, that was seven separate commands to fix "ding", and although one or two commands might be combined in if/else constructions, there's no doubt that fixing "ding" by hand in a spreadsheet would be simpler. The command-line method, however, avoids copy-down errors and is better suited to much larger files that have suffered at the hands of a dingbat.
Last update: 2019-02-24
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License