
For a full list of BASHing data blog posts, see the index page. ![]()
Fightin' fields
In a data table, how do you find data items in one field that contradict data items in another field? The hard part, I reckon, is deciding which fields to compare and what kind of disagreements should be looked for. You need to be a bit creative in this kind of data auditing!
The 3 examples in this post come from tab-separated tables of publicly available museum collection records. They've been compiled in what are called "Darwin Core" fields, which are more or less standardised categories of information in biological records.
The Darwin Core Task Group has published a neatly organised, 1-webpage reference guide to the Darwin Core categories.
True relationship? The first data table (here called "fish") consists of 99074 fish specimen records from the Museum of Southwestern Biology in Albuquerque, New Mexico, USA. Among the 53 non-empty fields are dwc:minimumDepthInMeters (field 33) and dwc:maximumDepthInMeters (field 31). Are the minimum and maximum figures all in the right order?
The question can be rephrased for AWK as follows: Ignoring the header line, and ignoring any records in which either minimum depth or maximum depth is blank, in how many records is the minimum less than the maximum [relationship true]? In how many records is the minimum greater than the maximum [relationship false]?
awk -F"\t" 'NR>1 && $31!="" && $33!="" && $33<$31' fish | wc -l #min<max
awk -F"\t" 'NR>1 && $31!="" && $33!="" && $33>$31' fish | wc -l #min>max

Almost 1 out of 6 records with minimum and maximum reversed? Better check that by sampling the first and last few values of a sorted and uniquified list of minimum and maximum pairs:
awk -F"\t" 'NR>1 && $31!="" && $33!="" && $33>$31 {print $33 FS $31}' fish \
| sort | uniq | head -n5 #printing minimum first, then maximum
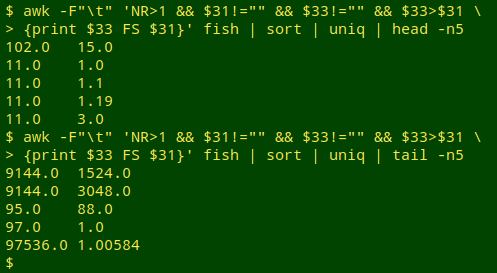
Yes, cleaning needed in 2716 records.
Logical problem? The next table ("mag2") contains 229039 fauna records from the Museum and Art Gallery of the Northern Territory, Darwin, Australia. In "mag2", eventDate (field 19) contains the date the museum specimen was collected, and dateIdentified (field 49) has the date when the specimen was assigned a scientific name. Both dates are in ISO8601 format: YYYY-MM-DD.
Logically, a specimen can't be identified before it's collected, but there are 2 records for which this is the case. Here I print catalogNumber, eventDate and dateIdentified for those 2 records:
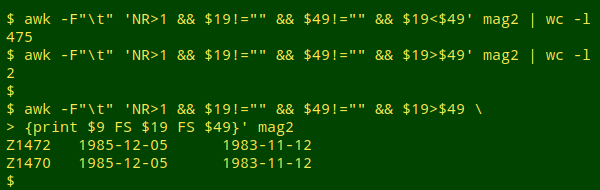
A check of "mag2" shows that the 2 records are for sponges collected by "Ward, T" off Port Hedland, Western Australia. Searching for all records with Ward as collector (recordedBy_raw, field 15) and printing eventDate (field 19) and locality_raw (field 42), then sorting and uniquifying the records, I see a possible reason for the disagreement between dates:
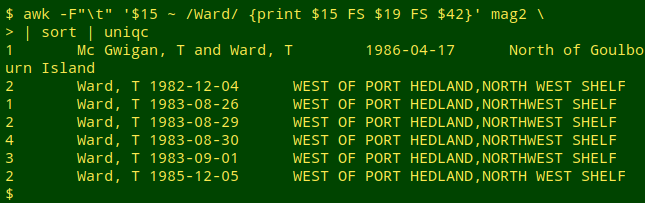
Looking at this list, my guess would be that "1985-12-05" in the 2 illogical records is a data entry error for "1982-12-05", but that's for the Museum to investigate.
Conversion fail? The third table ("ver1") contains 38668 arachnid specimen records from the Denver Museum of Nature and Science, Denver, Colorado, USA. The Museum has used the Darwin Core field startDayOfYear, which the reference guide says is The earliest ordinal day of the year on which the Event occurred (1 for January 1, 365 for December 31, except in a leap year, in which case it is 366). It's likely that the startDayOfYear field (field 29 in the dataset) is built from eventDate (field 28)
Converting eventDate to startDayOfYear for checking purposes turns out to be a fairly ugly operation in AWK. First the ISO8601 date from eventDate needs to be split into its year, month and day components with AWK's "split" function. The three components are then fed to the "mktime" function to get a UNIX-epoch timestamp for that date, in seconds. Finally, the timestamp is fed to the "strftime" function with "day of the year" output, "%j". Each step is shown below for the arbitrary date 18 June 1991; 18 June is the 169th day of the year:

In my checking command (below), the variable "b" stores an integral form of eventDate converted to a day-of-year. To test the command I'll look for sorted/uniquified records where the fields are in agreement, and print out eventDate, converted eventDate and startDayOfYear:
awk -F"\t" 'NR>1 && $28!="" && $29!="" {split($28,a,"-"); b = sprintf("%d",strftime("%j",mktime(a[1]" "a[2]" "a[3]" 0 0 0"))); if (b == $29) print $28 FS b FS $29}' ver1 | sort | uniq | tail
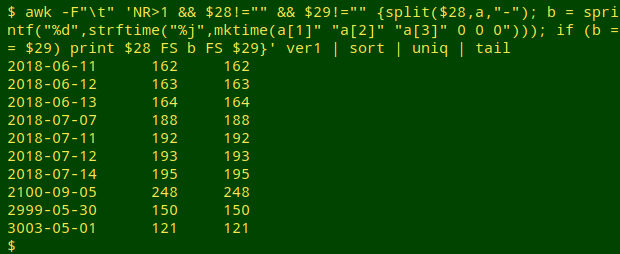
Well, that worked — even for future event dates like "3003-05-01"! (Memo to self: check for impossible eventDate years.) Now to look for failed conversions. In the output below I've added field 34, verbatimEventDate, which is normally the field from which eventDate is built.
awk -F"\t" 'NR>1 && $28!="" && $29!="" {split($28,a,"-"); b = sprintf("%d",strftime("%j",mktime(a[1]" "a[2]" "a[3]" 0 0 0"))); if (b != $29) print}' ver1 | wc -l
awk -F"\t" 'NR>1 && $28!="" && $29!="" {split($28,a,"-"); b = sprintf("%d",strftime("%j",mktime(a[1]" "a[2]" "a[3]" 0 0 0"))); if (b != $29) print $28 FS b FS $29 FS $34}' ver1 | sort | uniq -c | tail
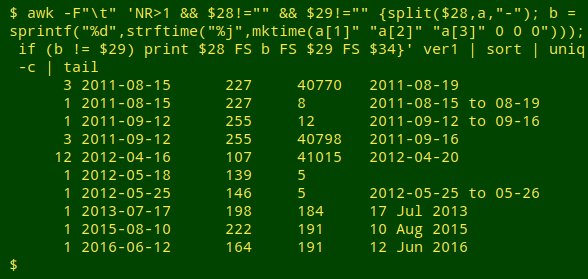
OK, startDayOfYear and eventDate both need cleaning.
Printing the output of "strftime" as an integer (sprintf("%d")) removes the leading zeroes in days-of-year like "004" and "067". If I didn't do that, the string comparison would fail, e.g. "067" would not be the same as "67" in startDayOfYear.
Those 5-digit startDayOfYear values seem to be Microsoft Excel serial dates in the 1900 system.
Last update: 2020-01-13
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License