
For a full list of BASHing data blog posts, see the index page. ![]()
Pseudo-blank ("empty") records and fields
It's easy to find records in a data table that are entirely blank or only contain tabs or whitespace. Just ask AWK to print the line numbers of any records that have no fields:
awk 'NF==0 {print NR}' datatable
or
awk '!NF {print NR}' datatable
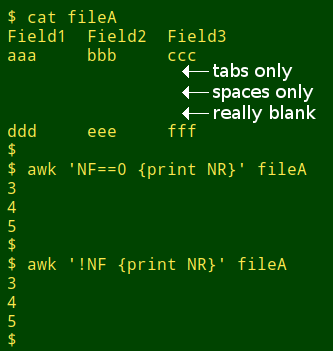
Blank records are fairly rare in real-world datasets. You're much more likely to find records that contain one or more essential data items (like a unique record ID) and nothing else, or maybe a "?" or "-" or two. These are "pseudo-blank" records. Three examples are on lines 4, 9 and 12 in the tab-separated table below, "fileB":
| RecordID | Last_name | First_name | CustomerID | Modified |
| 10001 | Albee | Michael | mel141a | 2018-08-01 |
| 10002 | Allan | Rebecca | war206a | 2018-08-01 |
| 10003 | ??? | 2018-08-01 | ||
| 10004 | Allan | ? | war206b | 2018-08-01 |
| 10005 | Allen | Georgina | mel097a | 2018-08-01 |
| 10006 | Amado | Paolina | mel141b | 2018-08-01 |
| 10007 | Andrewartha | Herbert | bri129a | 2018-08-01 |
| 10008 | 2018-08-01 | |||
| 10009 | Andrews | Samuel | syd322a | 2018-08-01 |
| 10010 | Antill | Jessica | hob111a | 2018-08-01 |
| 10011 | - | - | - | 2018-08-01 |
Cases like this are messy, but a general strategy for finding pseudo-blank records might be to count the fields with unexpected content, like fields without alphanumeric characters, then tally up the records by their suspect field counts:
awk -F"\t" 'BEGIN {c=0} {for (i=1;i<=NF;i++) if ($i !~ /[[:alnum:]]/) {c++}} {print "lines with "c" suspect fields"; c=0}' datatable | sort -r | uniq -c
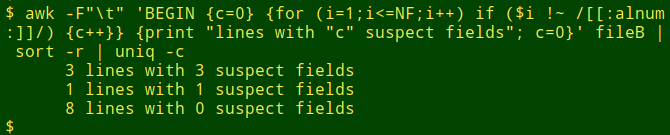
In the first part of the command, AWK goes through each tab-separated field in turn, testing it to see if it lacks alphanumeric characters. If it does, the variable "c" is incremented from zero, which was the value initialized in the BEGIN statement. When all fields in the record have been tested, AWK prints the field count "c", then resets "c" to zero. The output of the AWK command is fed to sort -r and uniq -c for a field count tally.
The next step is to print the records with the highest suspect field counts:

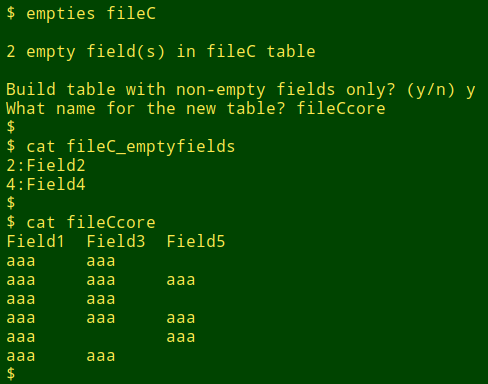
A data table might have a complete header line but only blank data items in some fields. These fields aren't completely empty, because they have a field name in the header, so they're "pseudo-blank". Finding these fields is fairly straightforward with AWK, and to do this I use the "empties" script explained below. To demo the script I'll use "fileC":
| Field1 | Field2 | Field3 | Field4 | Field5 |
| aaa | aaa | |||
| aaa | aaa | aaa | ||
| aaa | aaa | |||
| aaa | aaa | aaa | ||
| aaa | aaa | |||
| aaa | aaa |
The core of the script is a command that finds any fields that are empty below the header, and lists their field numbers:
awk -F"\t" 'NR>1 {for (i=1;i<=NF;i++) a[i]+=length($i)} END {for (j in a) {if (a[j]==0) print j}}' datatable

AWK here ignores the header line ("NR>1") and goes through the fields on each line one by one. For each field the "length" function calculates the number of characters and adds that number to an array "a" indexed by field number. An empty field will have a total character number of zero, which is what AWK looks for in the END statement when it walks through the array "a".
The complete "empties" script is shown below. The list of empty fields is stored in a temp file ("/tmp/flds"), as is a numbered list of all fields in the table ("/tmp/allflds"). If there are no empty fields in the table, the script reports that and exits. Otherwise, an AWK command uses an array to add a colon and a field name to each of the empty field numbers, saving the output as the file "[filename]_emptyfields". The number of empty fields is reported on screen, and the script asks if I'd like the data table with the empty fields removed. If I say yes, the new table is built with a name I choose.
#!/bin/bash
awk -F"\t" 'NR>1 {for (i=1;i<=NF;i++) a[i]+=length($i)} END {for (j in a) {if (a[j]==0) print j}}' "$1" > /tmp/flds
head -n1 "$1" | tr '\t' '\n' | nl -w1 > /tmp/allflds
if [ ! -s /tmp/flds ]; then
echo
echo "No empty fields in $1 table" && rm /tmp/flds /tmp/allflds && exit
else
awk -F"\t" 'FNR==NR {b[$1]=$2; next} $1 in b {print $1":"b[$1]}' /tmp/allflds /tmp/flds > "$1"_emptyfields
echo
echo "$(wc -l < "$1"_emptyfields) empty field(s) in "$1" table"
echo
read -p "Build table with non-empty fields only? (y/n) " build
if [[ "$build" == "y" ]]; then
read -p "What name for the new table? " name
cut --complement -f$(paste -d',' -s /tmp/flds) "$1" > "$name"
else
rm /tmp/flds /tmp/allflds && exit
fi
fi
rm /tmp/flds /tmp/allflds
exit
This script is much faster than the "empties" script I published in 2017 on the Linux Rain blog and in version 1 of A Data Cleaner's Cookbook.
Last update: 2020-01-13
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License