
For a full list of BASHing data blog posts, see the index page. ![]()
Truncated data items
truncated (adj.): abbreviated, abridged, curtailed, cut off, clipped, cropped, trimmed...
One way to truncate a data item is to enter it into a database field that has a character limit shorter than the data item. For example, the string
Yarrow Ravine Rattlesnake Habitat Area, 2 mi ENE of Yermo CA
is 60 characters long. If you enter it into a "Locality" field with a 50-character limit, you get
Yarrow Ravine Rattlesnake Habitat Area, 2 mi ENE #Ends with a whitespace
Truncations can also be data entry errors. You meant to enter
Sally Ann Hunter (aka Sally Cleveland)
but you forgot the closing bracket
Sally Ann Hunter (aka Sally Cleveland
leaving the data user to wonder whether Sally has other aliases that were trimmed off the data item.
Truncated data items are very difficult to detect. When auditing data I use three different methods to find possible truncations, but I probably miss some.
Item length distribution. The first method catches most of the truncations I find in individual fields. I pass the field to an AWK command that tallies up data items by field width, then I use sort to print the tallies in reverse order of width. For example, to check field 33 in the tab-separated file "midges":
awk -F"\t" 'NR>1 {a[length($33)]++} \
END {for (i in a) print i FS a[i]}' midges | sort -nr
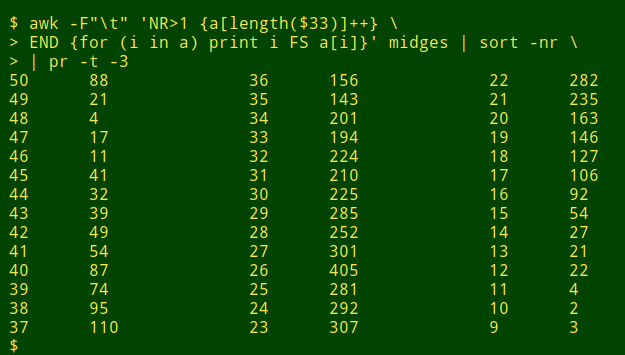
The longest entries have exactly 50 characters, which is suspicious, and there's a "bulge" of data items at that width, which is even more suspicious. Inspection of those 50-character-wide items reveals truncations:
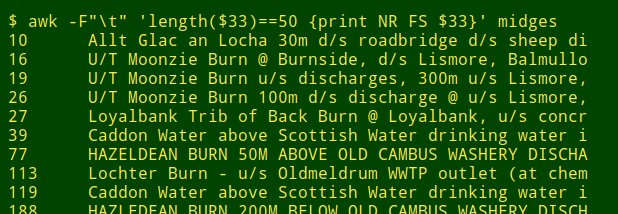
Other tables I've checked this way had bulges at 100, 200 and 255 characters. In each case the bulges contained apparent truncations.
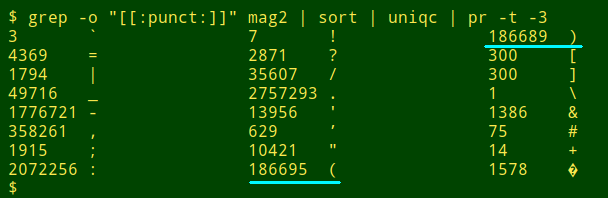
Unmatched brackets. The second method looks for data items like "...(Sally Cleveland" above. A good starting point is a tally of all the punctuation in the data table. Here I'm checking the file "mag2":
grep -o "[[:punct:]]" file | sort | uniqc
The strange-looking "uniqc" is an alias in my Linux setup. uniq -c right-justifies the count of unique results and separates count and result with a single space. The following alias left-justifies the count and separates it from the result with a tab character:
alias uniqc="uniq -c | sed 's/^[ ]*//;s/ /\t/'"
Note that the numbers of opening and closing round brackets in "mag2" aren't equal. To see what's going on, I use the function "unmatched", which takes three arguments and checks all fields in a data table. The first argument is the filename and the second and third are the opening and closing brackets, enclosed in quotes.
unmatched()
{
awk -F"\t" -v start="$2" -v end="$3" \
'{for (i=1;i<=NF;i++) \
if (split($i,a,start) != split($i,b,end)) \
print "line "NR", field "i":\n"$i}' "$1"
}
"unmatched" reports line number and field number if it finds a mismatch between opening and closing brackets in the field. It relies on AWK's split function, which returns the number of elements (including blank space) separated by the splitting character. This number will always be one more than the number of splitters:
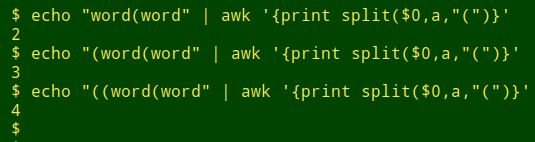
Here "ummatched" checks the round brackets in "mag2" and finds some likely truncations:
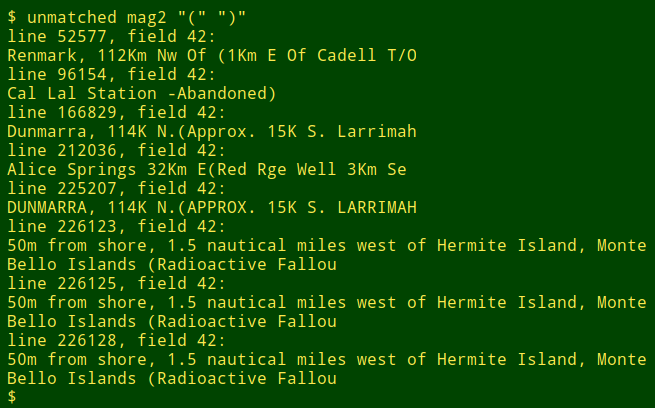
I use "unmatched" to locate unmatched round brackets (), square brackets [], curly brackets {} and arrows <>, but the function can be used for any paired punctuation characters.
Unexpected endings. The third method looks for data items that end in a trailing space or a non-terminal punctuation mark, like a comma or a hyphen. This can be done on a single field with cut piped to grep, or in one step with AWK. Here I'm checking field 47 of the tab-separated table "herp5", and pulling out suspect data items and their line numbers:
cut -f47 herp5 | grep -n "[ ,;:-]$"
awk -F"\t" '$47 ~ /[ ,;:-]$/ {print NR": "$47}' herp5
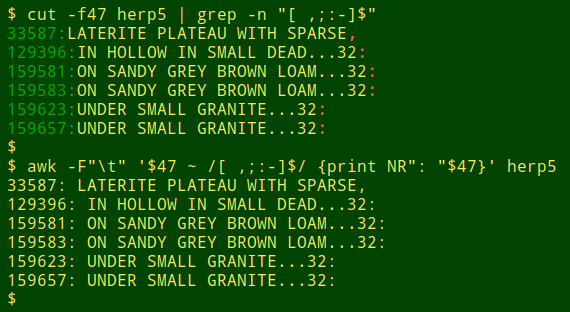
The all-fields version of the AWK command for a tab-separated file is:
awk -F"\t" '{for (i=1;i<=NF;i++) if ($i ~ /[ ,;:-]$/) \
print "line "NR", field "i":\n"$i}' file
Cautionary thoughts. Truncations also appear during the validation tests I do on fields. For example, I might be checking for plausible 4-digit entries in a "Year" field, and there's a 198 that hints at 198n. Or is it 1898? Truncated data items with their lost characters are mysteries. As a data auditor I can only report (possible) character losses and suggest that the (possibly) missing characters be restored by the data compilers or managers.
Last update: 2018-07-04
The blog posts on this website are licensed under a
Creative Commons Attribution-NonCommercial 4.0 International License